Seamless Support
with Lupitor

AI Voice Agents
Natural, human-like conversations powered by our Call Center as a Service platform.
Seamless Support
with Lupitor
AI Agents
Natural, human-like conversations
powered by our AI platform.

Trusted and used by 40+ clients





Have a custom demo in under 48 hours
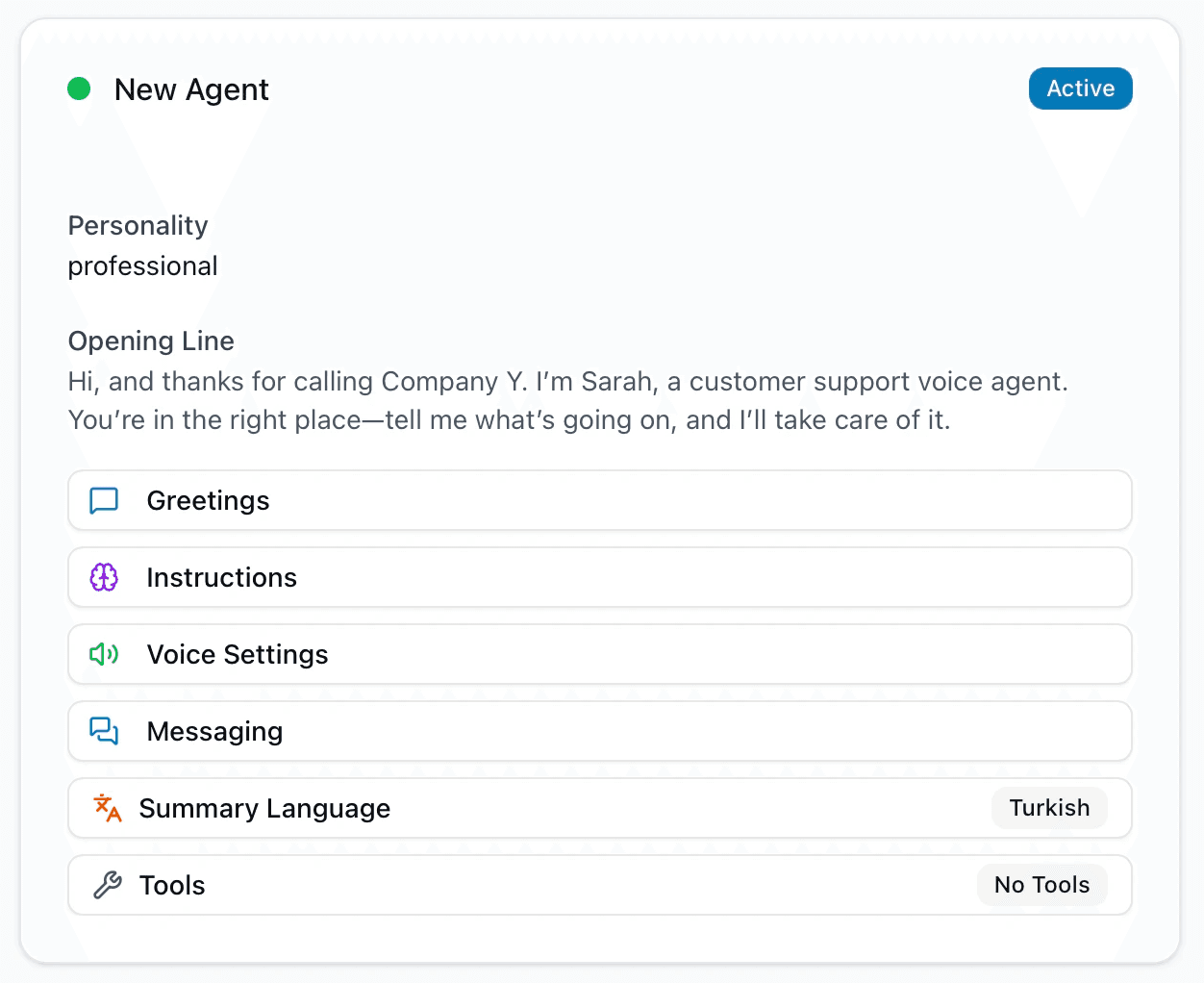
Bespoke agent and platform built to accomplish agreed-upon tasks just for you


Schedule a short discovery call to outline your use case.

Schedule a short discovery call to outline your use case.
Schedule a short discovery call to outline your use case.
You dream it
We listen. We build fast.




Thinking
Your tailored agent and platform, designed for your exact flow.

You dream it
We listen. We build fast.
Thinking
Your tailored agent and platform, designed for your exact flow.
You dream it
We listen. We build fast.
Thinking
Your tailored agent and platform, designed for your exact flow.
We deliver
Experience your live demo.

Powered By Lupitor AI
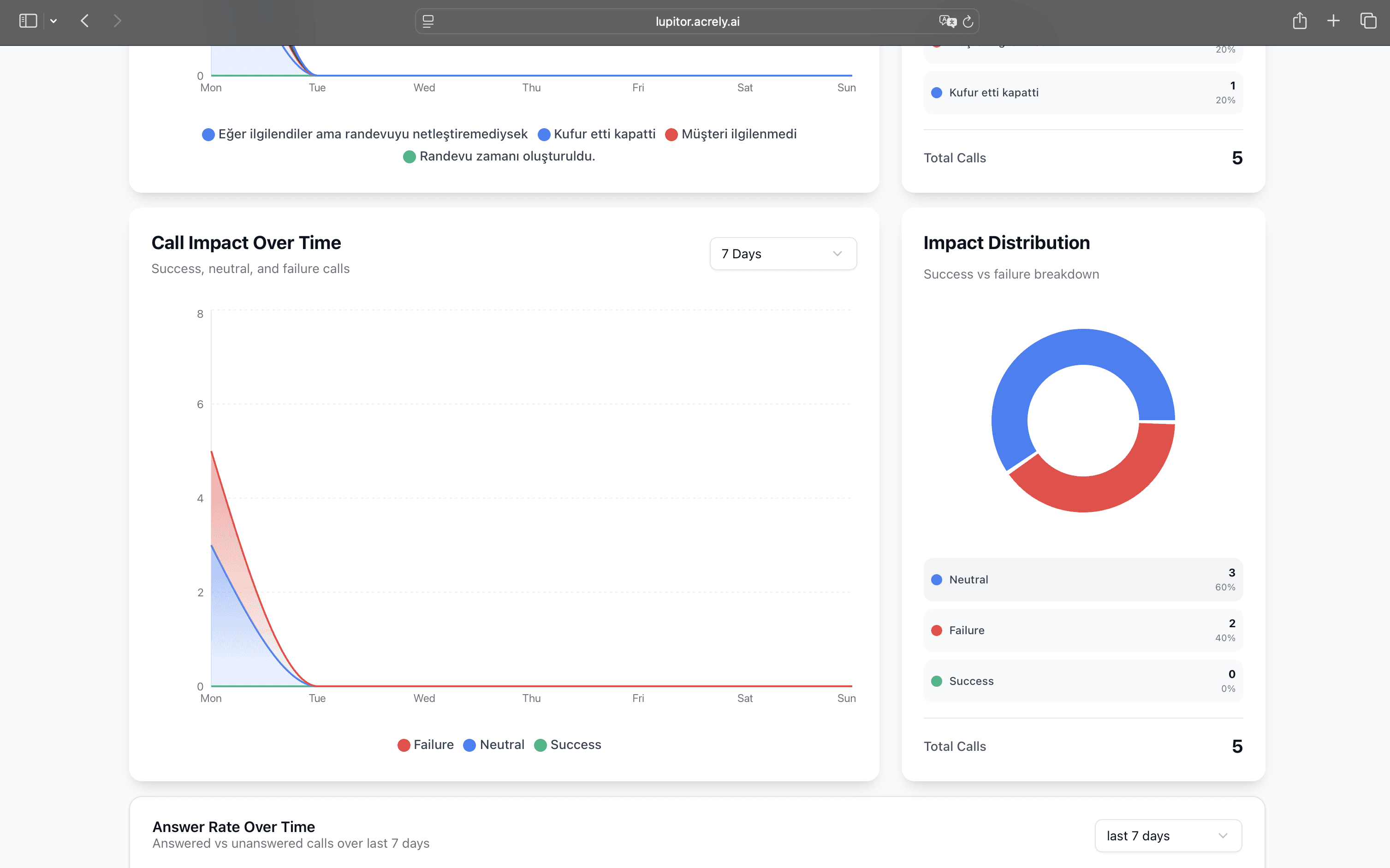

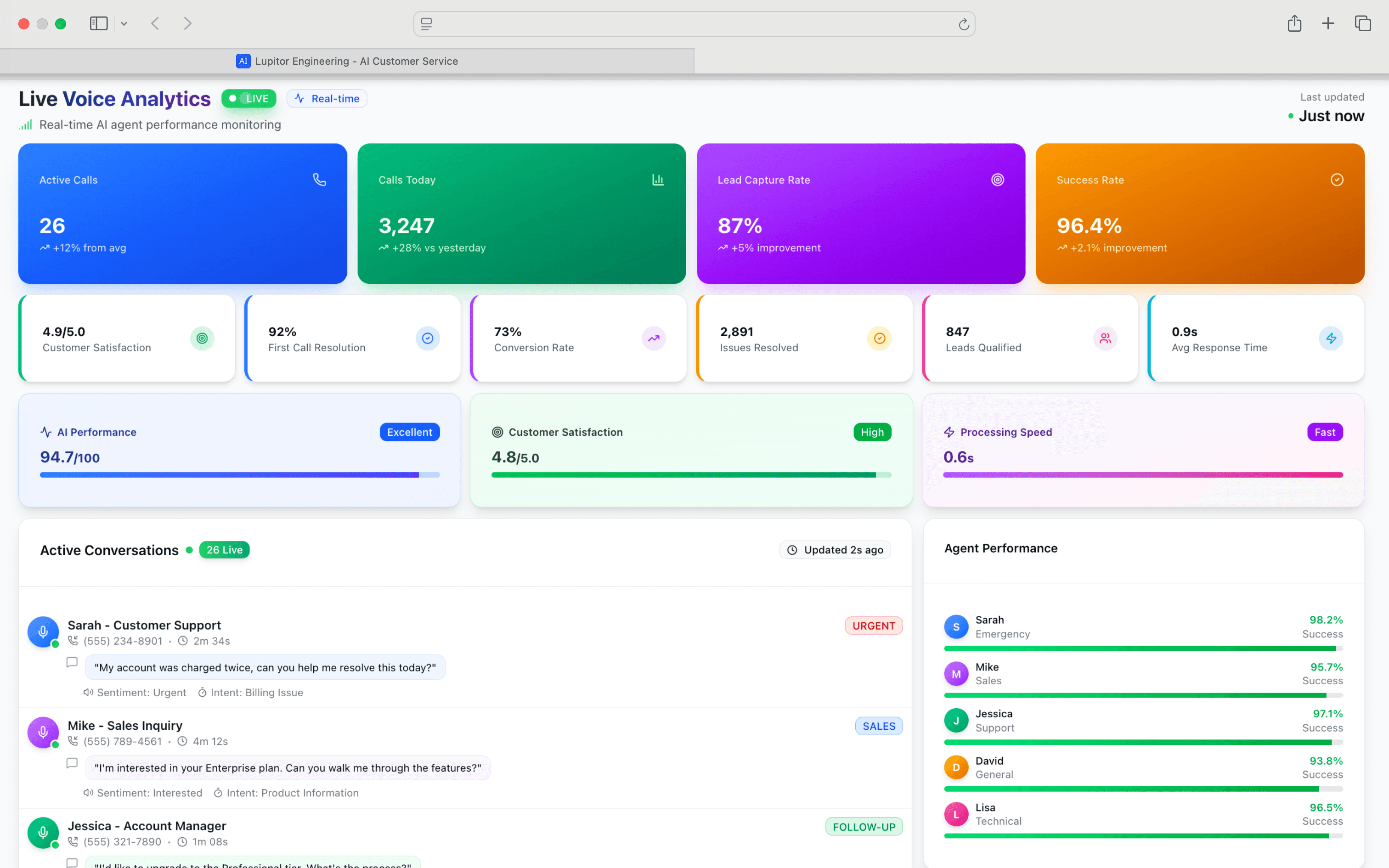
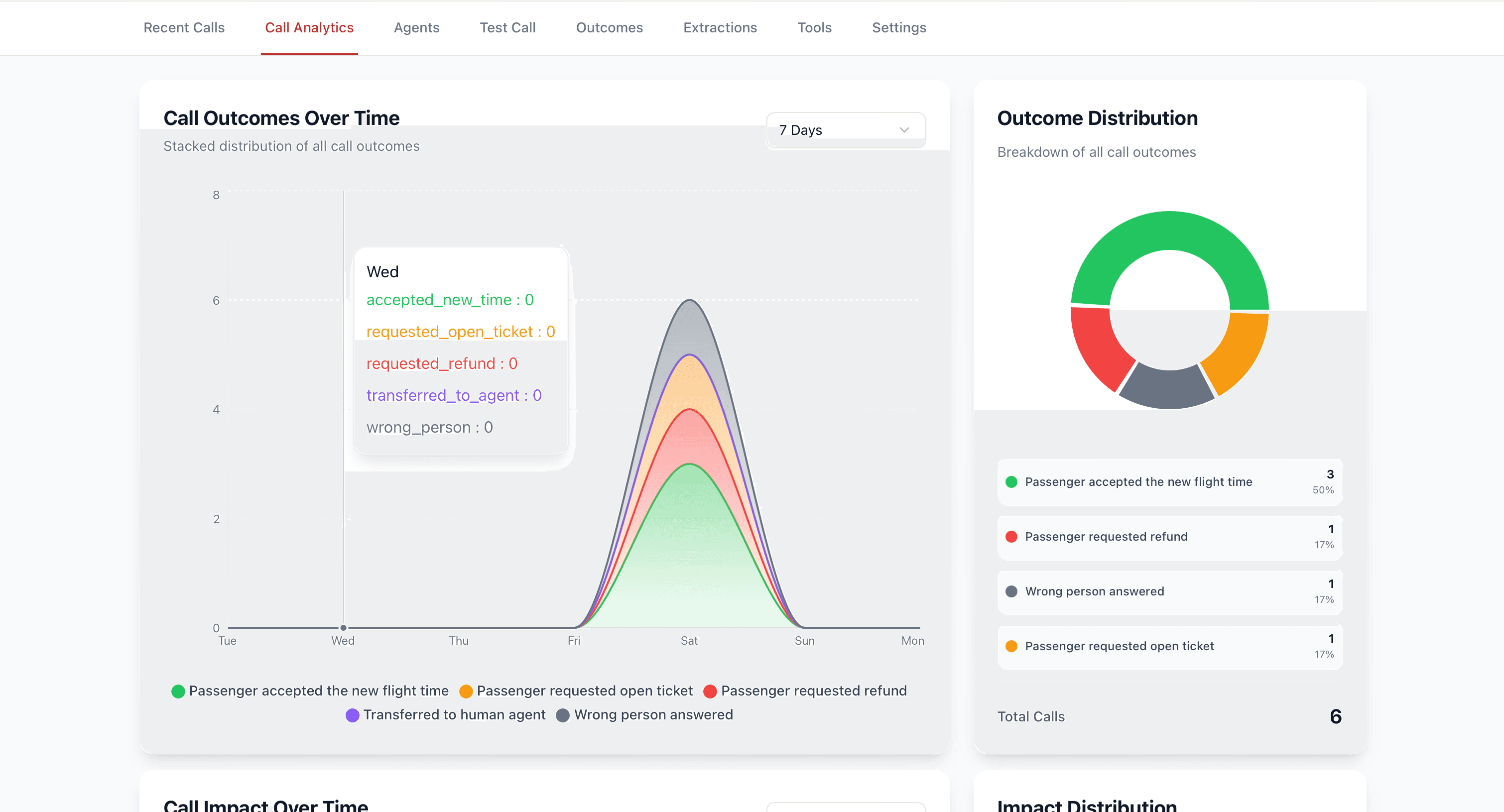
Test and observe your new AI voice agent and platform
We deliver
Experience your live demo.
Powered By Lupitor AI
Test and observe your new AI voice agent and platform
We deliver
Experience your live demo.
Powered By Lupitor AI
Test and observe your new AI voice agent and platform
Your new favorite employee. Always on,
never tired, never off script. Infinitely
scalable and completely under your control.
White-Glove Customer Care
AI Agents - built for the moments that matter.
Elevate every interaction with best-in-class customer service.
Omnichannel Support
Communicates seamlessly across voice, chat, and email.
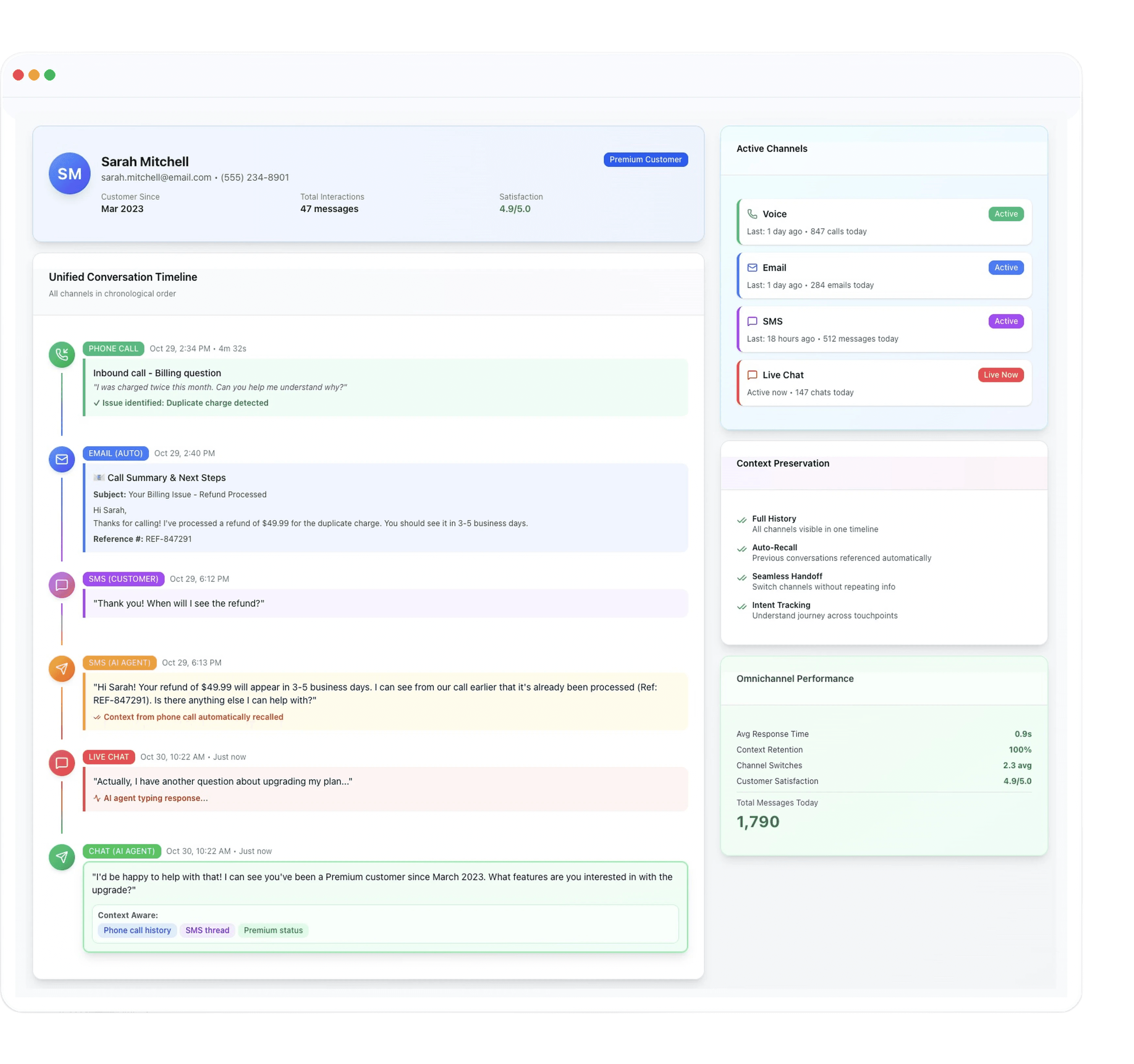
Omnichannel Support
Communicates seamlessly across voice, chat, and email.
Omnichannel Support
Communicates seamlessly across voice, chat, and email.
Instant Knowledge Recall
Delivers accurate, real-time answers from your data.

Instant Knowledge Recall
Delivers accurate, real-time answers from your data.
Instant Knowledge Recall
Delivers accurate, real-time answers from your data.

Self-Improving Agents
Continuously learns and adapts from every call.
Self-Improving Agents
Continuously learns and adapts from every call.
Self-Improving Agents
Continuously learns and adapts from every call.
Orchestrated Conversations
Follows your playbook precisely with built-in guardrails.
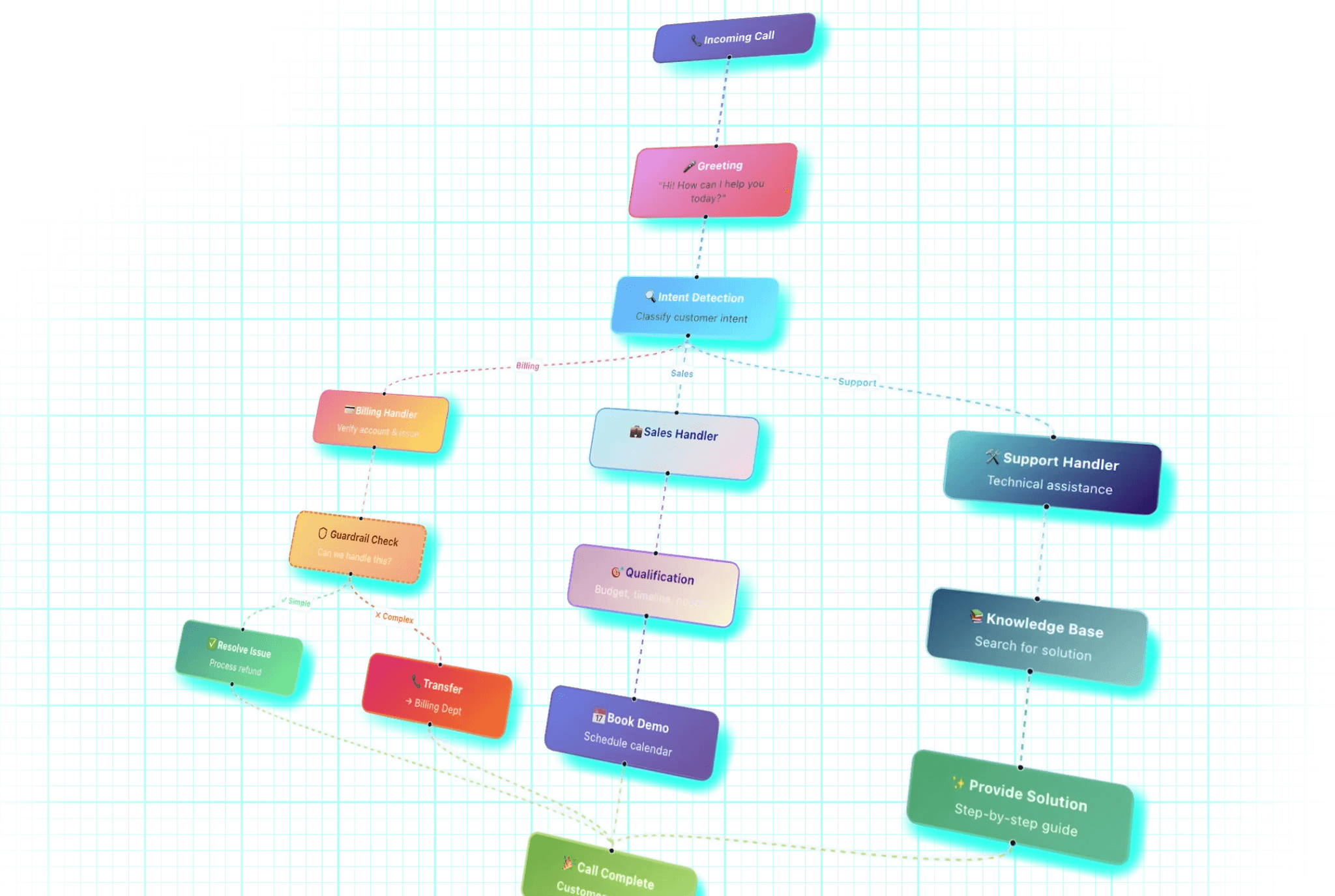
Orchestrated Conversations
Follows your playbook precisely with built-in guardrails.
Orchestrated Conversations
Follows your playbook precisely with built-in guardrails.

Integrations & Connected Apps
Integrate your entire support stack— CRM, documents, apps, and more














Ready to upgrade
your customer service?
Supercharge your contact center with a best-in-class
customer service automation platform.
Ready to upgrade
your customer service?
Supercharge your contact center with a best-in-class
customer service automation platform.
Frequently asked questions
Frequently asked questions
Everything you need to know.
Do you operate on-premise?
Yes. We provide full on-premise deployment with the same performance compared to cloud. Our custom-trained LLM maintains a 0.05% hallucination rate (HHEM test) and runs securely within your infrastructure.
Is it secure?
Does it work in any language?
Can it integrate with our existing systems?
Can it be customized for our brand or use case?
How is pricing structured?
Do you operate on-premise?
Yes. We provide full on-premise deployment with the same performance compared to cloud. Our custom-trained LLM maintains a 0.05% hallucination rate (HHEM test) and runs securely within your infrastructure.
Is it secure?
Does it work in any language?
Can it integrate with our existing systems?
Can it be customized for our brand or use case?
How is pricing structured?
Do you operate on-premise?
Yes. We provide full on-premise deployment with the same performance compared to cloud. Our custom-trained LLM maintains a 0.05% hallucination rate (HHEM test) and runs securely within your infrastructure.
Is it secure?
Does it work in any language?
Can it integrate with our existing systems?
Can it be customized for our brand or use case?
How is pricing structured?
